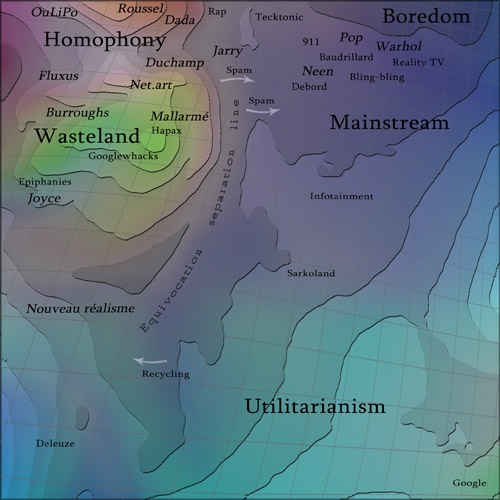
| A map of language at large
scale You may simply watch the maps below and try
to figure out what they mean. If you want to understand how
they were generated, please read the Concept
and Methodology sections. As
described there, the first steps consist in extracting massive
amount of information from Google and analyzing it in terms
of semantics and homophony. From this complex and time-consuming
procedure we get some geometrical description of language,
considered here as the hypergraph of words and pages that
is stored in Google's database.
The first thing to understand is that each pixel of the map
corresponds to one couple of words - and not to one word.
This looks quite non-intuitive but remember we are mainly
interested in correlations between words.
We started from a lexicon of several thousands of words
which correspond to about 800 000 couples (as many pixels
then), and we looked for homophonic correlations, as in billard
/ pillard, or for semantic correlations.
More precisely our procedure provides three measurements
for each couple of words corresponding to
1) Homophony
Homophony between two
words tells how much both words look like each other. In our
context it is measured thanks to so-called Damerau-Levenshtein
distance, a standard procedure in information theory.
2) Google Similarity (or semantic relatedness)
The Google
Similarity distance reflects the semantic relatedness
of both words. This distance is smaller when both words are
closely related, ie. when they tend to appear more often in
the same webpages.
3) Equivocation.
It tells how much a word
has a univocal meaning or at the contrary is polysemic or
equivocal. In the case of a graph it is related to the clustering
coefficient. Technically we take the minimum of this coefficient
for a given couple of words.
We associate homophony with Red, Google
Similarity with Green (but in inverse relationship) and Equivocation
with Blue (in inverse relationship). Each pixel has a colour
defined by its (Red,Green,Blue) components, therefore each
couple of words is associated with a (R,G,B) triplet. This
self-organizing map is generated with a neural network that
gathers together pixels of similar (R,G,B) (more explanation
here).
Interpreting the different zones
 Although this map could be used to locate
any couple of words (it will be so in the next version of
the map that will be interactive), the main objective is to
define different zones of language, using the three criteria
mentionned above: Homophony, Google Similarity (semantic relatedness)
and Equivocation. By considering the different boundaries
of each coefficient we can build regions which have quite
simple interpretations: Although this map could be used to locate
any couple of words (it will be so in the next version of
the map that will be interactive), the main objective is to
define different zones of language, using the three criteria
mentionned above: Homophony, Google Similarity (semantic relatedness)
and Equivocation. By considering the different boundaries
of each coefficient we can build regions which have quite
simple interpretations:
Homophony - High
homophony region.
Wasteland - Low relatedness: couples of words
that are barely used in the same contexts and have very few
in common. A zone from where new significations and surprises
emerge (friche or jachère in french).
Mainstream - High relatedness: words are
strongly correlated to each others and everything is very
predictable.
Utilitarianism - Low equivocation: each word
has a univocal meaning and there is no place for ambiguity.
At the end of the Mainstream region lies the kingdom of Boredom.
Finding precise boundaries for these different
zones is for the moment an impossible task. We just don't
know how to define scales, separating what is big from what
is small. The Equivocation Separation Line
that delimits the high equivocation zone from the low equivocation
zone is not therefore very precisely located and it is not
our aim to claim that we have localized it with accuracy.
A region of particular interest is the
one with high homophony, high relatedness and high equivocation.
This is what we called the Dada region and
it was the starting point of our study. It is the red region
at the top left of the map. If this zone is big, then mankind
is very Roussellian or Dada. Of course Dada is not limited
to this region and goes beyond the range of this map.
Since we are
not able yet to find out the precise borders between the different
zones, it is difficult to define precisely what would be the
value of a such a global index as the Dadameter, wich is somehow
supposed to measure the size of the Dada region. We probably
need to make some arbitrary normalization, but the study of
the dynamics would be important here since the variations
with time of such indexes would certainly tell us a lot. We
leave these questions for further developments.
Also you shouldn't be mistaken by the fact
that two region's names are very close on the map. It just
mean that they share some characteristics (the three we have
defined in this study), but not all of them of course. As
for the stars in the sky, they may sometimes look close and
in the same constellation but are very far away in reality.
However, the light rays that come out from them do travel
on close paths.
We can now superimpose two other types of entities: first,
media phenomenon and second, artists and artistic movements.
Among media phenomenon you will find Hapax
or Googlewhacks. They are
somewhere in the region where relatedness is at its lowest. A hapax is a word that appear once and only once in literature
(most famous one is by Stéphane Mallarmé). A
Googlewhack is a couple of words that appears in only one
page of the web, as it is reported by Google.
Spam streams are marketing linguistic flux
from Wasteland to Mainstream. They are also related to Homophony:
spambots cheat on anti-spam filters by using words like Viaa.gr*a
instead of Viagra. Spam streams are not a region, they belong
to the dynamical aspect of the problem for which there is
no quantitative analysis yet. These questions might be taken
into account in future studies, but because of the difficulty
to obtain all these information, the analysis of their evolution
in time is a very difficult task. On the left of Wasteland,
the Epiphanies as defined by James
Joyce. They are a way to destroy the totalization of meanings
and lie not far from the left limit of the map where signification
breaks down.
This zone out of Signification, decay
of the Imaginary, is situated outside of the map. Jacques
Lacan had made a correlation between the collapse of Joyce's
narcissism ie. the decay of the Imaginary, and the role that
the epiphanies play in his work. Outside of the map above
Dada we have situated the decay of the Symbolic, following
this article by Jean-Claude
Maleval which relates this vanishing point of enunciation
to the episodes of mental crisis in the life of Roussel where
he felt having the glory ("avoir la gloire"). As
Joyce's writing would be, according to Lacan, an attempt to
make up the decaying Imaginary, Roussel's work, according
to Maleval, shows an attempt to artificially restore the Symbolic
through a mechanisation of language. Here we assume that this
inflation of the Imaginary dimension in Roussel's work is
actually a premonition of Pop, to
be opposed to the vanishing narcissism of Joyce. It is interesting
to relate this with the idea that Pop Art is an answer to
Walter Benjamin's decay
of the aura, following Baudrillard's comment in
De la marchandise absolue. It is also quite understandable
that this Pop region does not lie very far the kingdom of
Boredom, one of Warhol's favorite words. On the other hand
the positionning of Pop doesn't really reflect its essential
irony, in relation to the fetichism of commodity. We reach
here the limits of such a cartographic representation.
In between those two decays, semantic
capitalism and Taylorisation
of speech stretch away. Modernity may be here identified
with Utilitarianism and a bit of Mainstream (but not Boredom),
but in principle it also contains some of the Avant-Gardes
on the top-left... although I would personnaly consider some
of them more as percursors of Postmodernity. The Spam streams
from the Wasteland region towards the Mainstream and Utilitarianism
regions, are of particular interest. This mechanism might
be compared to the processes of the very origins of capitalism,
namely the rise of agrarian
capitalism around Renaissance. Wasteland is used as a
Temporary Autonomous Zone for renewing Capitalism always threaten
by Boredom and extinction of desire.
* * *

|