|
Il est possible que vous trouviez ces théories criticables dans la mesure où elles tendent à considérer le langage comme un corps sans vie, qui serait étudié post-mortem... une sorte d'autopsie du langage plongé dans un état d'agonie permanent. Vous auriez sans doute raison.
Cependant, dans le cadre du capitalisme post-industriel, ces outils jouent un rôle de plus en plus important et il semble naturel de s'y intéresser, si l'on veut savoir ce que l'avenir nous réserve. Le but de ces dispositifs mathématiques et informatiques est simplement de prédire nos pensées et nos comportements à des fins commerciales ou politiques. Ils jouent par exemple un rôle crucial dans l'optimisation du système des Adwords..
Il est aussi à noter que Shannon possédait des hobbies non dénués d'intérêt sur le plan conceptuel. Un des dispositifs les plus amusants qu'il construisit était une boite qui s'appellait "Ultimate
Machine", basée on sur une idée de Marvin Minsky. Sans fonction aucune, la boite possédait un seul interrupteur sur le côté. Lorsque l'interrupteur était enclenché, le couvercle s'ouvrait, un bras mécanique sortait pour fermer l'interrupteur, puis retournait dans la boite. En un sens, le Dadamètre ressemble à cette machine ultime, mais dans le champ du langage et à l'age de la
globalisation... comme si la cause du langage se trouvait dans sa propre mort.
Etape
1 : extraîre massivement les données textuelles de Google
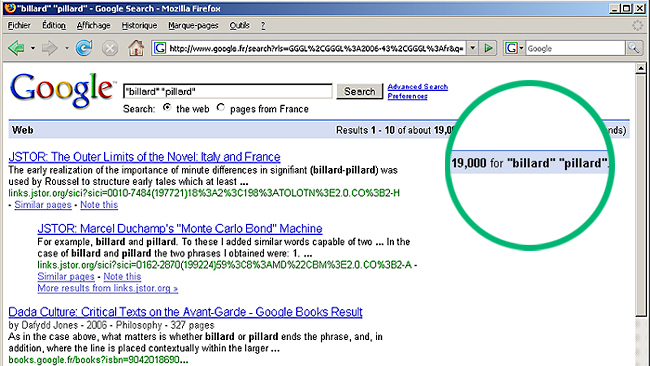
Le Dadamètre concerne le langage à grande échelle et nécessite une extraction massive de l'information que Google stocke dans ses bases de données. Plus précisément les données qui nous intéressent ici sont les suivantes : quel que soit le couple de mots, on cherche à connaitre le nombre de pages Web qui contiennent les deux mots à la fois. Ces quantités permettent de calculer les corrélations entre deux mots différents, ie. la probabilité d'aller d'un mot à un autre, si l'on considère le langage comme un hypergraphe global de mots et de pages. Ces nombres sont donnés par Google, comme on le voit sur la copie d'écran ci-dessus.
Nous commençons par construire des listes de mots. Dans le cas présent nous sommes partis d'une liste d'environ 7000 mots courants. Il s'agit ensuite d'extraire les quantités ci-dessus pour environ 2.5 millions
de couples de mots (7000 x 7000 / 2). Dans la mesure où nous nous intéressons aux mots qui sont proche homophoniquement les uns des autres, notre liste de couples se réduit en fait à environ 800 000.
Ces nombres sont donnés par les moteurs de recherche. Cependant comme nous avons besoin de ceux-ci pour une grande quantité de couples, il est nécessaire de construire un programme qui scanne les pages des moteurs de recherche. Le problème est alors que ce type de programme est rapidement détecté et considéré comme un virus. L'adresse IP de l'ordinateur sur lequel tourne le programme est alors bloquée (comme je l'ai dit, ces données permettent aux moteurs de recherche de faire des prédictions sur nos comportements et nos désirs, et ont donc un intérêt stratégique si nous les considérons dans leur globalité, bien qu'ils soient sans valeurs pris un par un). Une solution est de diminuer la vitesse du scan pour faire croire que le programme est en fait un être humain qui fait des recherches sur le Web (pour tout dire, nous n'avons même pas utilisé Google mais un autre moteur, car Google nous détectait trop rapidement. A notre niveau d'approximation les résultats sont indépendants de ce choix. Nous continuons à mentionner de Google dans la mesure où ce nom propre est pratiquement devenu un nom commun du langage courant - NdT : c'est vrai dans la langue anglaise, "to google" ayant fait son entrée dans le Oxford English Dictionary en 2006).
Conceptuellement cette situation de turing-test inverse
est intéressante, mais en pratique cela retarde considérablement notre entreprise ! Cela nous a pris plus de deux mois pour télécharger l'information dont nous avions besoin, en utilisant 5 ordinateurs connectés à l'Internet avec des adresses IP différentes. Les moteurs de recherche ont construit leur puissance en scannant l'ensemble de toutes les pages Web de l'humanité et maintenant l'humanité ne peut plus avoir accès à ses propres données ! En principe ces données ces données ne sont pas le propriété des moteurs de recherche, puisqu'elles appartiennet encore à leurs auteurs (chacun d'entre nous). Mais la substance raffinnée qui est extraite de cette matière première est très certainement la propriété des moteurs, si nous nous en tenons aux lois des sociétés capitalistes (on pourrait prétendre qu'il s'agit de co-propriété mais cet argument serait certainement rejeté au cours d'un procès).
Etape 2 : analyser cette
information grâce aux découvertes récentes en théorie des graphes, pour avoir un aperçu de la structure à grande échelle du langage, en termes d'homophonie et de sémantique
L'information extraite de Google comme décrit ci-dessus, nous permet de classer les couples de mots selon le critère de proximité sémantique. Comme on le verra, des formules mathématiques permettent de réaliser cela dans le cadre de la théorie des graphes. Mais tout d'abord, reprenons à notre point de départ, à savoir la méthode de Raymond Roussel, et intéressons-nous à l'autre aspect de la question : l'homophonie, qui est plus facile d'accès.
1 - en terme d'homophonie : la distance de Damerau-Levenshtein
La question de l'homophonie dans le cadre de la théorie de l'information a été étudiée depuis les années 1950. La distance de Damerau-Levenshtein permet de mesurer la différence entre deux séquences (ie deux mots écrits) et donc d'évaluer leur ressemblance homophonique (la question de l'homophonie n'est pas entièrement décrite par cette quantité puisqu'elle concerne l'écrit et non pas le niveau phonétique,
mais cela sera suffisant pour notre cas et correspond assez bien à la méthode de Roussel -
bien qu'il ait fait un usage plus large de l'homophonie). Par exemple la distance de Damerau-Levenshtein entre «billard»
et «pillard» est faible (elle vaut 1 selon la
définition ci-dessous). La distance de Damerau-Levenshtein entre
«kitten» et «sitting» vaut 3, puisqu'il faut au moins trois transformations pour passer d'un mot à l'autre :
kitten --> sitten
(substitution de 's' à 'k')
sitten --> sittin
(substitution de 'i' à 'e')
sittin --> sitting (insertion de
'g' à la fin)
En théorie de l'information, la distance de Damerau–Levenshtein
est une «distance» entre deux chaines de caractères, donnée par le nombre minimum d'opérations nécessiare pour transformer un chaîne en l'autre, les opérations permises étant l'insertion, la suppression ou la substitution d'un seul des caractères ou la permutation entre deux caractères.
La première phase de notre travail a donc été le calcul des distances de Damerau–Levenshtein
entre les 7000 x 7000 / 2 couples. C'est la partie facile de la procédure.
2 - en terme de proximité sémantique :
Google Similarity distance
Très récemment d'importants progrès ont été réalisés en théorie des graphes et en linguistique quantitative. Un article de 2005 de Rudi L. Cilibrasi et Paul M.B. Vit´anyi,
a défini une (pseudo-)distance appelée Google
Similarity Distance (ou Normalized Google Distance) qui reflète la proximité sémantique entre deux mots, et qui utilise l'information contenue dans les moteurs de recherche (cf Etape 1). La
distance entre deux mots est d'autant plus petite lorsque les deux mots sont fortement corrélés, c'est-à-dire lorsque ils tendent à apparaître plus souvent ensembles dans les mêmes pages Web.
Cette Normalized Google Distance est en fait une amélioration d'une formule plus simple et plus compréhensible qui définit la similarité entre deux mots a et b, par :
s(a, b) = f(a,b) / sqrt (f(a) x f(b)) = Nombre de pages contenant
à la fois a et b divisé par la racine carrée de (Nombre de pages contenant
a × Nombre de pages contenant
b).
Puis d(a, b) = 1 — s(a,b) correspond à la dissimilarité entre les deux mots.
Cette distance dépend des chiffres que nous avons extraits de Google. Après avoir scanné environ 800 000 pages de résultats de recherches, nous avons pu obtenir ces quantités pour les
7000 e les 800 000 couples de mots. Les résultats sont impressionnants et semblent correspondre assez bien à l'intuition sémantique, ainsi que le font remarquer Cilibrasi et Vit´anyi.
3 - en terme de degré d'équivoque : clustering
coefficient
Le coefficient
du clusterisation sur un graphe est un concept plus complexe encore. Il nous intéresse dans la mesure où il permet, sur un graphe sémantique, de définir le degré de polysémie ou d'équivoque d'un mot (principe également utilisé par Roussel dans sa méthode). Intuitivement si un mot appartient à deux cluters il tendra à avoir deux sens différents. Si un mot appartient à un cluster unique, son sens sera certainement univoque.
De récentes études ont montré que les coefficients de clusterisation sur un réseau sémantique sont reliés à une notion de courbure sur le graphe. Dans notre cas, il s'agit en fait d'un hypergraphe et nous avons dû utiliser un article de 2007 au sujet des graphes valués.
D'un point de vue technique, nous considérons le minimum de ce coefficient pour un couple de mots donné.
Les résultats deviennent ici très difficile à vérifier et à interpréter. Ce coefficient est fonction de l'entier voisinage d'un mot et le calcul de sa valeur exacte est pour l'instant hors de notre portée. Il nous manque une grande partie de l'information nécessaire et nous avons dû faire des approximations dont la validité n'est pas clairement établie. Cependant nous espérons que notre étude jettera un nouvel éclairage sur la question.
Il était important, au moins sur le plan qualitatif, de prendre en compte cet aspect de la question car il joue un rôle important dans la méthode de Roussel, et car il nous a permis de conceptualiser notre approche en terme de cartographie d'une manière intéressante et inattendue. Si vous vous reportez à la section Dadamap, la région de l'Utilitarisme et la ligne d'Equivoque,
sont directement reliées à cette approche en terme de coefficient de clusterisation.
Etape 3 :
visualiser ces structures grâce à des cartes, des graphes ou des indices globaux,
puis interpréter les résultats
Nous sommes maintenant en possession d'une imposante liste de chiffres et nous souhaitons interpréter et visualiser cette information. C'est un problème difficile mais pas désespéré. Deux techniques sont envisageables ici : les cartes auto-adaptatives et la visualisation sous forme de graphes.
1) Une carte auto-adaptative constitue une technique standard et très utile pour visualiser des projections d'espaces de données de grande dimension, tout en préservant ses propriétés topologiques. Ces cartes sont générées grâce à des réseaux de neurones qui regroupent les pixels de couleurs similaires. Le modèle a été introduit en tant que réseau de neurones artificiels par le finandais
Teuvo Kohonen, et est parfois appelé carte de Kohonen. Voici un exemple montrant comment une telle carte se forme avec une faible quantité de données. Au début, les pixels colorés sont choisis au hasard, puis ils s'auto-organisent. La section
Dadamap présente l'interprétation des différentes régions de la carte, et constitue le résultat principal de notre étude.
2) Finalement, nous avons utilisé les données extraites pour construire un graphe interactif que vous trouverez à la section R.R.Engine.
|